
作者:litianc
时间:2026年4月7日
阅读时长:12分钟
前言
如果你觉得今天的大模型最让人头疼的问题是幻觉,那你大概还没有在一个持续数周、甚至数月的项目里和它真正共事过。
真正让人崩溃的,往往不是它偶尔答错,而是它总会在最关键的时候忘记你们已经讨论过什么。你明明和 Claude、ChatGPT、Cursor 反复聊过架构权衡、踩坑记录、Debug 过程和团队偏好,可一旦对话窗口切换、上下文过长、会话中断,这些高价值信息就像被冲进了下水道。
MemPalace 真正抓人的地方,不只是分数和热度,而是它试图把 AI 的长期记忆从“摘要缓存”改造成“可翻阅的档案空间”。也正因为如此,它才会这么快被很多人看成这个方向上一颗过于耀眼、以至于必须认真研究的“皇冠明珠”。
先说我的结论:MemPalace 最值得看的,不是某个
96.6%的很抓眼球的高分,也不是“名人关联”这层故事,而是它提出了一种更像样的 AI 记忆观。这种记忆观不是让模型自己总结一份用户画像,而是让模型先拥有一座可检索、可唤醒、可回到原文、还能保留时间关系的外部档案系统。
本文主要基于 GitHub 仓库、BENCHMARKS.md、提交记录和少量外部公开线索来写。关于 “Milla Jovovich / Aya The Keeper” 这层叙事,我的判断也比最初更明确了:这已经不像单纯的同名账号或挂名传播,而更像是真实参与。但这篇文章的重点仍然是项目本身,所以这部分只点到为止。
一、为什么 MemPalace 会在短时间内引爆讨论
如果只把它看成一个技术项目,MemPalace 的传播速度其实有点不寻常。它能这么快出圈,我觉得是因为它同时叠了五层叙事。
| 维度 | MemPalace 给出的叙事 | 为什么容易传播 |
|---|---|---|
| 痛点 | AI 会失忆,长期项目上下文留不住 | 这是开发者和重度 AI 用户的共性痛点 |
| 方法 | store everything, then make it findable |
这个表达非常直观,几乎一句话就能讲明白 |
| 形态 | 本地运行、零 API key、MCP 可接入 | 既降低门槛,又符合当下 agent 工具生态 |
| 高分 | LongMemEval 高分、README 直接打榜 | 社区天然会对 benchmark 排名敏感 |
| 故事 | 名人关联叙事、自述背景、Ben Sigman、提交记录 | 技术话题突然具备了传播性和八卦性 |
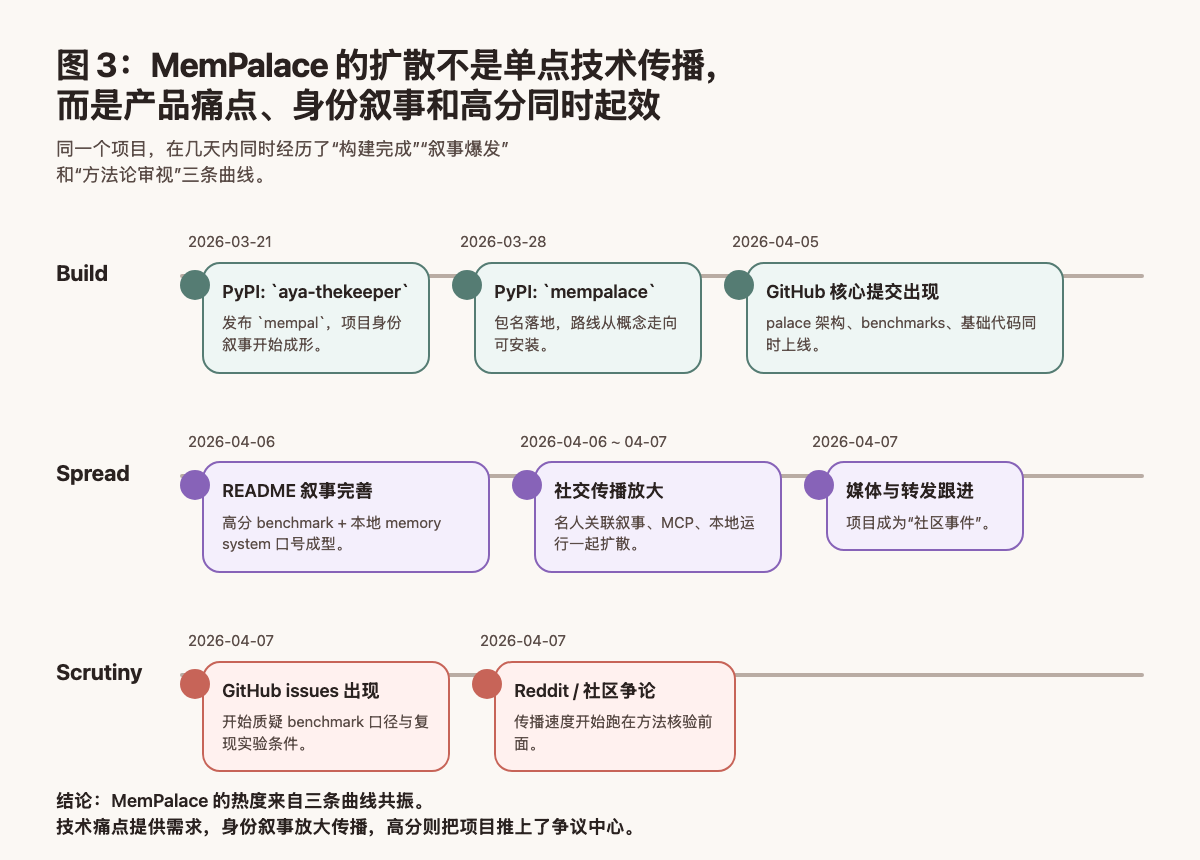
也就是说,MemPalace 的扩散不是单靠某一个点完成的,而是“真实痛点 + 好记的产品隐喻 + 本地化技术主张 + 高分 benchmark + 高辨识度身份叙事”共同作用的结果。
这里有一个现象可以客观提一句,但不值得写成整篇文章的中心:围绕 Milla Jovovich / Aya The Keeper 的这层身份叙事,现在已经不只是传播噱头。仓库在她名字对应的账号下,前 7 次可见提交里有 4 次由 milla-jovovich authored,外部也有合作方公开把项目描述为两人共同打造。换句话说,把她理解成真实参与者,比理解成单纯的流量包装,更符合目前能看到的证据。
这也解释了为什么它在 GitHub 上线后很快就不只是一个 repo,而更像一场带剧情、有争议、也有方法论悬念的开源发布。
二、它真正重写的,不是搜索,而是记忆的形状
先说一句结论:MemPalace 真正试图重写的,不是“搜索”本身,而是“AI 记忆应该以什么结构存在”。
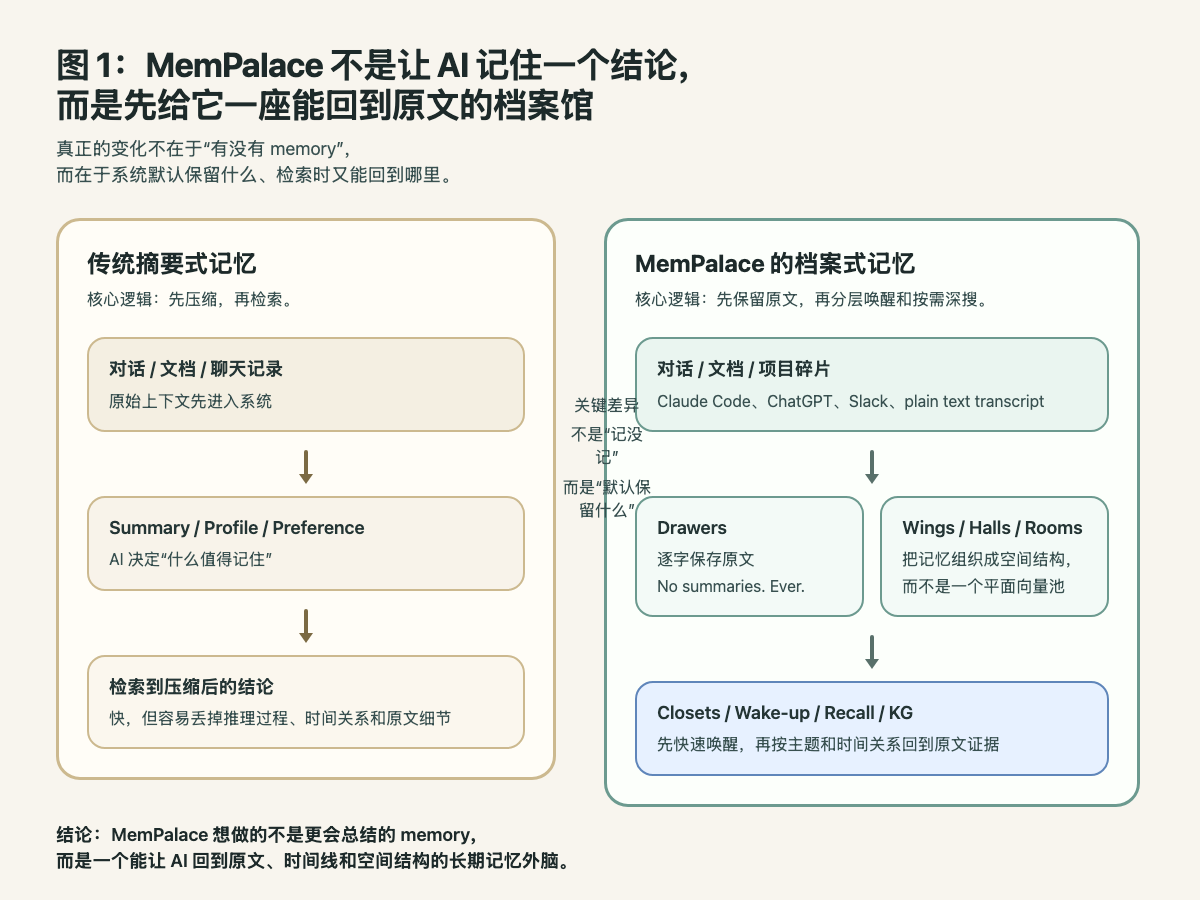
README 里的核心主张很明确:很多现有 memory 系统的做法,是让 AI 自己决定“什么值得记住”,然后把这些内容压成用户画像、偏好摘要或者事件摘要。问题在于,这样很容易丢掉原始推理过程。MemPalace 的路线则是反过来:先尽量保留原文,再通过结构和检索去解决可用性问题。
从仓库代码和 README 来看,它大致由几层东西组成:
| 结构 | 作用 | 对应含义 |
|---|---|---|
wing |
顶层域 | 某个人、某个项目、某个主题 |
hall |
分类层 | 事实、事件、发现、偏好等记忆类型 |
room |
主题单元 | 一个更具体的议题,比如 auth-migration |
closet |
压缩速览层 | 用于快速唤醒和浏览的简化内容 |
drawer |
原文层 | 保留 verbatim 文本,不做二次总结 |
tunnel |
跨域连接 | 在不同 wing 之间连起同主题 room |
这个设计直接借用了“记忆宫殿”的空间隐喻,但它不只是命名好听。代码里确实有 palace_graph.py 这类模块,把这些空间关系真正做成可遍历的结构。因此,MemPalace 不是简单给向量库加了一层 UI,而是试图把“空间化结构”本身变成检索的先验。
如果顺着使用路径去理解,它的思路其实很清楚:先 ingest 各种聊天和文档,把原文放进 drawer,再在上层做 wake-up、closet 和按需 recall。换句话说,它试图解决的是一个非常现实的问题:怎么让 AI 在不把整个历史上下文一次性塞进 prompt 的情况下,还能保留“翻原文”的能力。
三、四个最值得抓住的技术点
如果从传播角度看,技术拆解不能写成“模块点名册”。读者最容易接受的,不是 mcp_server.py、normalize.py、dialect.py 这些文件名,而是四个更直觉的问题:
- 为什么 AI 记忆不能只做摘要?
- 为什么不能只靠向量搜索?
- 为什么长记忆不是把 prompt 变得更长?
- 为什么记忆还必须知道什么已经过期?
3.1 它先解决了一个最根本的问题:不要让 AI 先替你遗忘
这一点是我觉得 MemPalace 最值得重视的地方。
很多 memory 系统的默认前提都是:先把历史压成 summary、profile、preference,然后再把这些压缩结果交给模型。但问题在于,一旦系统先替你决定“什么重要”,它也就顺手替你丢掉了很多之后可能会重新变重要的东西。
MemPalace 的立场刚好相反。它强调 drawer 层保留 verbatim text,搜索时也尽量回到原始内容,而不是优先返回系统加工后的结论。这个设计的传播力其实很强,因为它一下就能把用户痛点说透:
- 你要的往往不是“我们最后选了 Postgres”
- 你真正想找回的是“我们为什么没选 MySQL”
换句话说,MemPalace 不是先做一个更聪明的摘要器,而是先做一个不轻易替你忘事的档案系统。
3.2 它真正的特色,不是名字叫 palace,而是把检索做成了“先找房间,再找证据”
MemPalace 最容易被当成 branding 的部分,其实恰恰是它最像方法论的部分。
仓库把记忆按 wing / hall / room 组织,而不是直接把所有文本扔进一个平面向量库。这样做的直觉非常符合人类理解复杂信息的方式:很多长期记忆问题,不是“找最像的句子”,而是“先确定这件事属于哪个空间,再在那个空间里找证据”。
这也是为什么我觉得这个项目传播上最聪明的一点,不是它说自己更强,而是它给了读者一个非常容易复述的心智模型:
- 一个项目是一侧 wing
- 一类记忆是一条 hall
- 一个具体议题是一间 room
只要这个模型成立,读者就能立刻明白它为什么不只是另一个本地 RAG 工具。它试图做的是带方向感的检索,而不是更大力出奇迹的搜索。
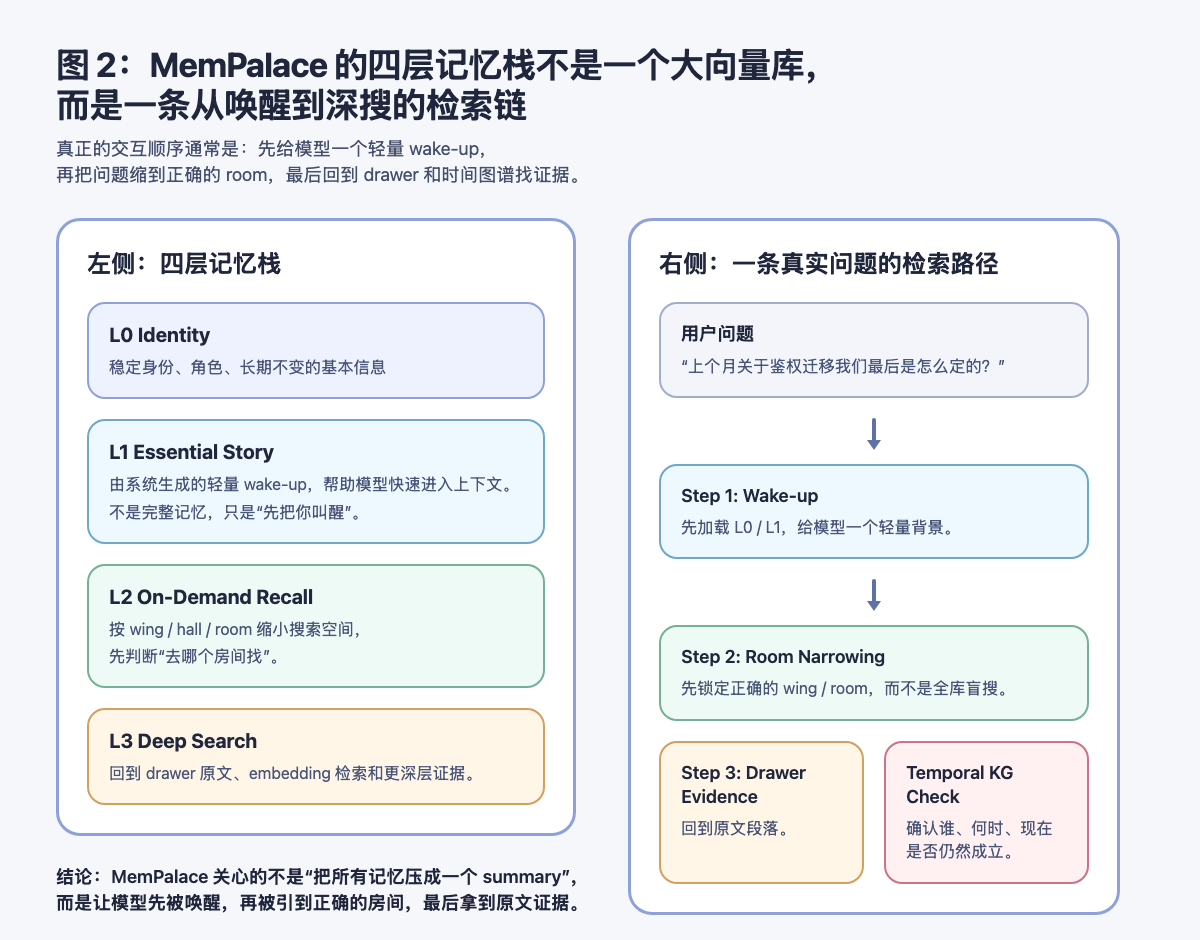
3.3 它把长期记忆拆成“唤醒层”和“深搜层”,而不是幻想一次把所有上下文塞进去
这是 MemPalace 里另一个很容易被忽视、但非常重要的点。
很多人一谈长期记忆,第一反应就是想办法把更多历史塞进 prompt,或者想办法做更猛烈的压缩。MemPalace 给出的答案更接近系统设计:不要把长期记忆当成一坨静态上下文,而要把它拆成不同成本、不同精度的层。
从它的四层记忆栈看,这套思路大致是:
- 先用 L0 / L1 做轻量 wake-up
- 再用
wing / room把搜索范围缩小 - 最后才回到 drawer 和更深层检索拿证据
AAAK 在这里最值得理解的,也不是某个漂亮的压缩数字,而是它服务的这个大方向:让模型先快速进入背景,而不是一上来就背整座仓库。
这个点从传播上也特别容易被读者接受,因为它回答的是一个非常现实的问题:长期记忆不是“记得更多”,而是“该先想起什么,该稍后再深挖什么”。
3.4 它给记忆补上了“时间感”,这一点比很多人想的更重要
另一个我认为特别关键的模块是 temporal knowledge graph。
很多记忆系统只能回答“有没有见过类似内容”,但对于长期项目来说,这远远不够。真正难的是下面这种问题:
- 这个决定是现在仍然有效,还是三个月前有效?
- 这个任务到底是王五负责,还是后来已经转给李四?
- 这条经验是长期规则,还是某次故障后的临时 workaround?
MemPalace 用本地 SQLite 去维护带时间语义的知识图谱,这件事的价值就在于:它让记忆不只是“记住文本”,还开始尝试“记住事实的生效区间”。
这对传播也很重要。因为一旦你把问题说成“AI 终于知道哪些结论已经过期”,读者马上就能意识到,这不只是一个搜索体验优化,而是在向更像“工作记忆系统”的方向走。
除了这四个技术点,MemPalace 还有两个很重要的落地加分项:一是它对真实工作流输入更友好,能 ingest 聊天记录、导出文件和工程碎片;二是它可以通过 MCP 融入 agent 工作流。前者让它更容易落地,后者让它更有未来感。但如果从读者接受度来看,这两点更适合放在“它可以拿来做什么”里展开,而不是和核心技术点抢主舞台。
四、五个现实落点
真正让人兴奋的,不是 MemPalace 又多了一个本地向量库封装,而是它可能把“AI 记忆”从聊天附属功能,变成一种新的工作基础设施。
4.1 长期项目外脑
这是我觉得最现实的场景。
今天很多人已经在用 Claude Code、Cursor、ChatGPT 辅助开发,但这些工具的上下文天然是碎片化的。真正决定项目走向的,往往不是最后合并进仓库的代码,而是一路上那些没有被正式写进 ADR 的讨论:为什么从 REST 改成 GraphQL,为什么放弃某个依赖,为什么这次权限迁移要拆两阶段做。
这些东西,恰恰最容易丢。
如果 MemPalace 真能稳定把聊天记录、代码讨论、事故总结和项目文档串起来,它最先成立的形态很可能不是“AI 有了人格化长期记忆”,而是项目终于有了一颗外置大脑。你不再只是问“现在代码是什么样”,而是可以问“这个项目为什么会变成今天这样”。
4.2 新人入门
很多团队的 onboarding 文档都不算少,但新人真正卡住的地方,往往不是“找不到文档”,而是“看到了结论,却不知道上下文”。
比如文档会告诉你:
- 我们统一用 Postgres
- 鉴权走内部网关
- 某个服务暂时不能拆
但不会告诉你:
- 当时为什么不用 MySQL
- 为什么鉴权没有直接交给云厂商托管
- 为什么这个服务一拆就会牵动账务
这类“决策前史”恰好是 MemPalace 想保存的东西。它的价值不是替代正式文档,而是补上正式文档背后的讨论层。对于团队 onboarding 来说,这可能比再写一份更长的 Wiki 更有用。
4.3 有履历的专家 Agent
README 里最容易让人想象的一件事,就是给不同 agent 配不同记忆。
比如:
- 一个 code review agent,长期记住这个代码库过去被拒绝过哪些模式
- 一个架构 agent,长期记住团队过去做过哪些折中
- 一个研究 agent,长期记住你平时关心的话题、来源偏好和追问路径
这类场景之所以值得看,不是因为“agent 更聪明”了,而是因为它终于可能有履历了。
过去很多 agent 的问题是,每次都像第一天上班。MemPalace 这种系统如果真的融入 MCP 工作流,某些 agent 才有机会从“一次性工具”变成“带历史经验的协作者”。
4.4 本地隐私知识库
MemPalace 的另一个潜在吸引力,是它天然适合那些不愿意把上下文长期交给云端托管的团队。
如果你要保存的是:
- 内部会议纪要
- 客户沟通记录
- 故障复盘
- 研究笔记
- 带敏感信息的项目文档
那么“本地运行、零 API key、SQLite + ChromaDB” 这种组合,本身就是一种产品态度。它未必最炫,但它很符合很多组织真实的采用门槛。
4.5 真正的门槛
当然,把这些场景说出来很容易,真正做成并不简单。
它至少还有几道坎要过:
- ingestion 质量能不能长期稳定,尤其是跨来源格式混杂时
- room / hall 这种空间结构,在大规模数据下会不会变得难维护
- AAAK、closet、wake-up 这些中间层,能不能在不同模型上保持稳定收益
- benchmark 优势能不能转化成真实工作流里的持续收益
所以更准确的说法不是“MemPalace 已经把这些场景都跑通了”,而是:它已经把一条很值得追的路线摆在了桌面上。
五、那个高分到底有多硬
MemPalace 能这么快火起来,一个很直接的原因,就是它把分数打得足够亮眼。也正是这种亮眼,才让“它是不是皇冠明珠”这个问题变得既诱人,又必须谨慎。
96.6% 本身当然已经很高了,文档里甚至还给出了 100% 这样的结果。但问题也正出在这里。读者第一眼看到的,往往只是那个最显眼的数字;真正决定这个分数有没有说服力的,其实是后面的条件。
从 BENCHMARKS.md 往下看就会发现,它不是只给出了一种跑法,而是混合了几种设置:
- 有纯本地、不额外调用模型的结果
- 也有加了 rerank 的结果
- 有些数字是在更强设置下跑出来的
- 文档里甚至自己也给了更保守的说法
所以这件事真正该问的,不是“它有没有高分”,而是:这个高分到底是在什么条件下拿到的,换个人按同样条件还能不能跑出来。
也正因为如此,社区的质疑很快就集中到了几个特别朴素的问题上:
- 文档首页和细节说明之间,有没有让人误解的地方?
100%这种结果,是不是强依赖 rerank 或额外设置?- 如果换成独立的人来复跑,结果还能不能站住?
我觉得现在最合适的态度,不是急着吹,也不是急着踩,而是把问题说简单一点:
MemPalace 的分数很亮眼,但它真正要证明的,不是“我能写出一个高分”,而是“别人也能按同样方法跑出这个高分”。
如果它后面能做到这一点,那这个项目就不只是会讲故事,而是真的把方法做硬了。就算最后有些分数口径需要回调,它至少也已经把“AI 记忆该怎么测、该怎么比”这件事重新推到了台前。
六、结论:MemPalace 也许不是终局,但它把问题问对了
MemPalace 最值得看的,不是一个很抓眼球的高分,也不是那层自带传播性的故事,而是它把 AI 长期记忆这件事重新讲明白了。
它提醒大家,真正像样的记忆系统,不该只是更长的上下文窗口,也不该只是一个更大的向量库。它应该能回到原文,能分层唤醒,能理解时间,能把“知道结论”和“拿出证据”分开。
哪怕以后它的 benchmark 口径还会继续被修正,MemPalace 仍然已经做成了一件重要的事:它让“AI 记忆”第一次不再像一个抽象功能,而像一套正在成形的外部认知系统。它是不是这条赛道上的皇冠明珠,也许还要再等一轮时间来回答;但它至少已经让人看见,这顶皇冠大概会长什么样。
参考资料:
- MemPalace GitHub 仓库,https://github.com/milla-jovovich/mempalace
- MemPalace benchmark 文档,https://github.com/milla-jovovich/mempalace/blob/main/benchmarks/BENCHMARKS.md
- MemPalace 提交历史,https://github.com/milla-jovovich/mempalace/commits/main/
milla-jovovichGitHub 主页,https://github.com/milla-jovovich- Ben Sigman 相关公开传播线索抓取,https://instalker.org/JeremyNguyenPhD


