
作者:litianc
时间:2025年7月4日
阅读时长:7分钟
引言
在红杉AI峰会2025上,红杉资本合伙人Pat Grady提出了”万亿美元机会”的观点——下一轮AI浪潮中,卖的不是工具,而是收益。这句话既是对用户为AI付费的范式转移的总结,也为AI应用开发团队指明了方向,Agent的实用性将成为每个AI应用开发者首要关注的问题。
“跟进DeepSeek部署”系列文章原本的重点是企业AI的技术工具实践,围绕能产生价值的共性工具来设计选题。结合行业发展趋势,本文将是该系列的最后一篇文章。这里极力推荐读者关注Deep Research这项技术,它有望成为企业从AI中获得收益的重要通道。
什么是Deep Research?
浙大团队近期发表的《深度研究的全面综述:系统、方法论和应用》中,对Deep Research给出了较为完整的定义:
“深度研究(Deep Research)是指通过三个核心维度,系统性地应用人工智能技术来自动化和增强研究过程:
- 智能知识发现:自动化跨异构数据源的文献检索、假设生成和模式识别;
- 端到端工作流自动化:将实验设计、数据收集、分析和结果解释整合到统一的AI驱动管道中;
- 协作智能增强:通过自然语言界面、可视化和动态知识表示促进人机协作。”
简而言之,Deep Research是一项能够自主调用复杂研究工具、根据用户需求输出详实且有条理报告的技术。它不仅仅是大模型对话、单一AI助手或搜索引擎工具的组合,而是一个综合性的智能研究工具。
Deep Research 不是某一家大模型公司的专属产品,而是一类技术的统称。据调查,当前市面上有超过80种Deep Research相关产品,我们耳熟能详的OpenAI、Google Gemini、Anthropic都推出了自家的Deep Research产品。
从运行过程来看,Deep Research充分展现了大模型在自主规划、工具使用、反思以及多智能体协作等方面的强大能力。这是Google Gemini团队开源的DeepResearch项目界面。

从benchmark跑分结果来看,Deep Research能够取得比原先最先进的大模型更好的得分,这是OpenAI发布Deep Research时的测试结论。
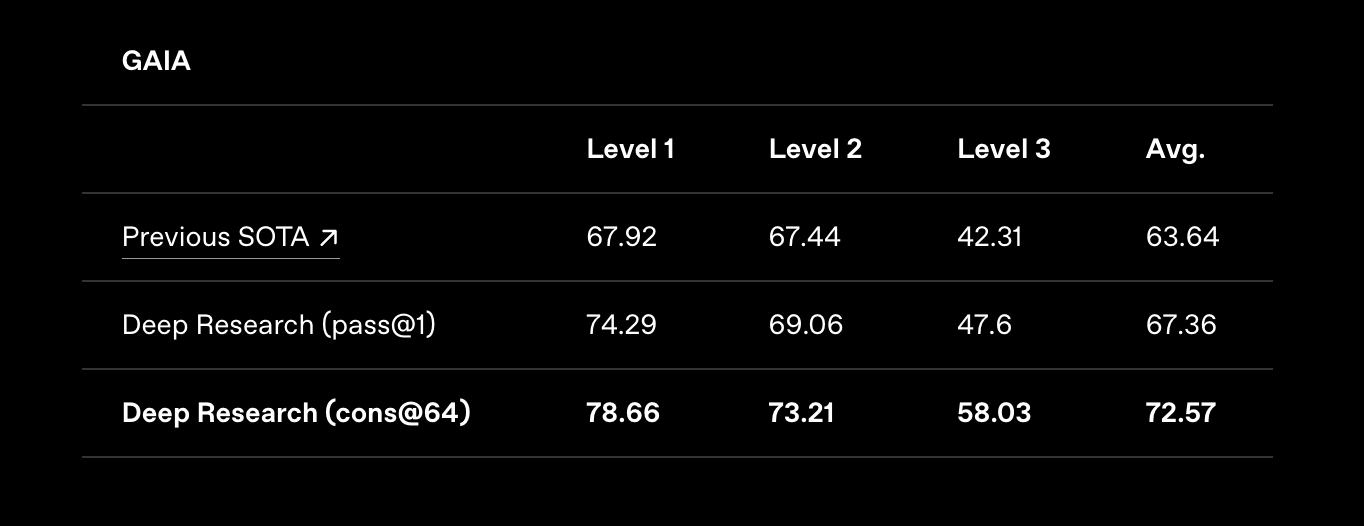
Deep Research的工作原理
Deep Research 的设计模式
在目前已公开的近百种 Deep Research(深度研究)产品中,根据系统设计方式的不同,主要可以分为四种类型:单体架构、流水线架构、多智能体架构,以及混合架构(流水线+多智能体)。下面用更通俗的方式解释这四种架构的区别:
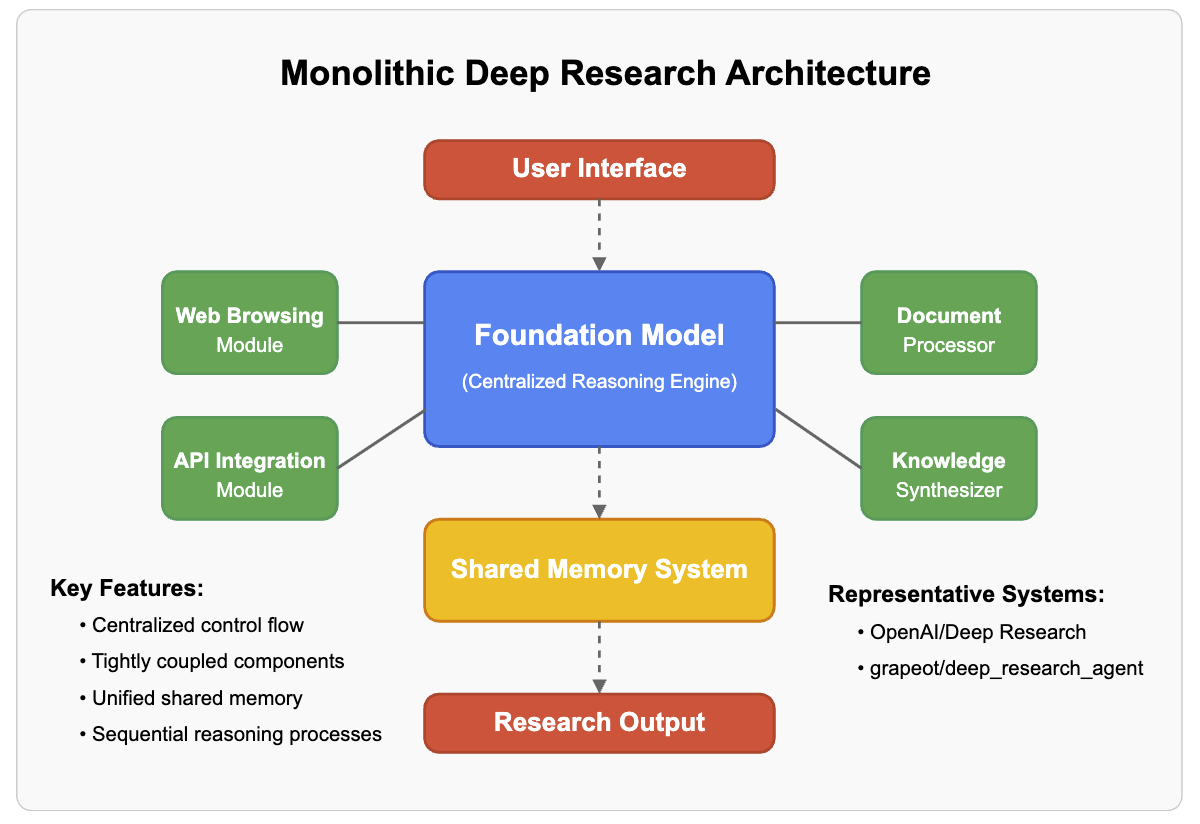
- 单体架构(Monolithic)—— “全能型选手”
- 核心特点:所有功能都集成在一个”大模型”里,就像一台超级计算机,所有任务都由它自己完成。
- 工作方式:
- 只有一个核心推理引擎(可以理解成”大脑”),负责所有计算和决策。
- 所有数据、状态和执行逻辑都集中管理,没有模块化拆分。 * 优点:简单直接,适合小规模任务。 * 缺点:扩展性差,一旦任务复杂或数据量大,可能会变慢或难以维护。 * 类比:就像一个人既要负责搜索资料、分析数据、写报告,还要做最终决策,所有事情都自己干。
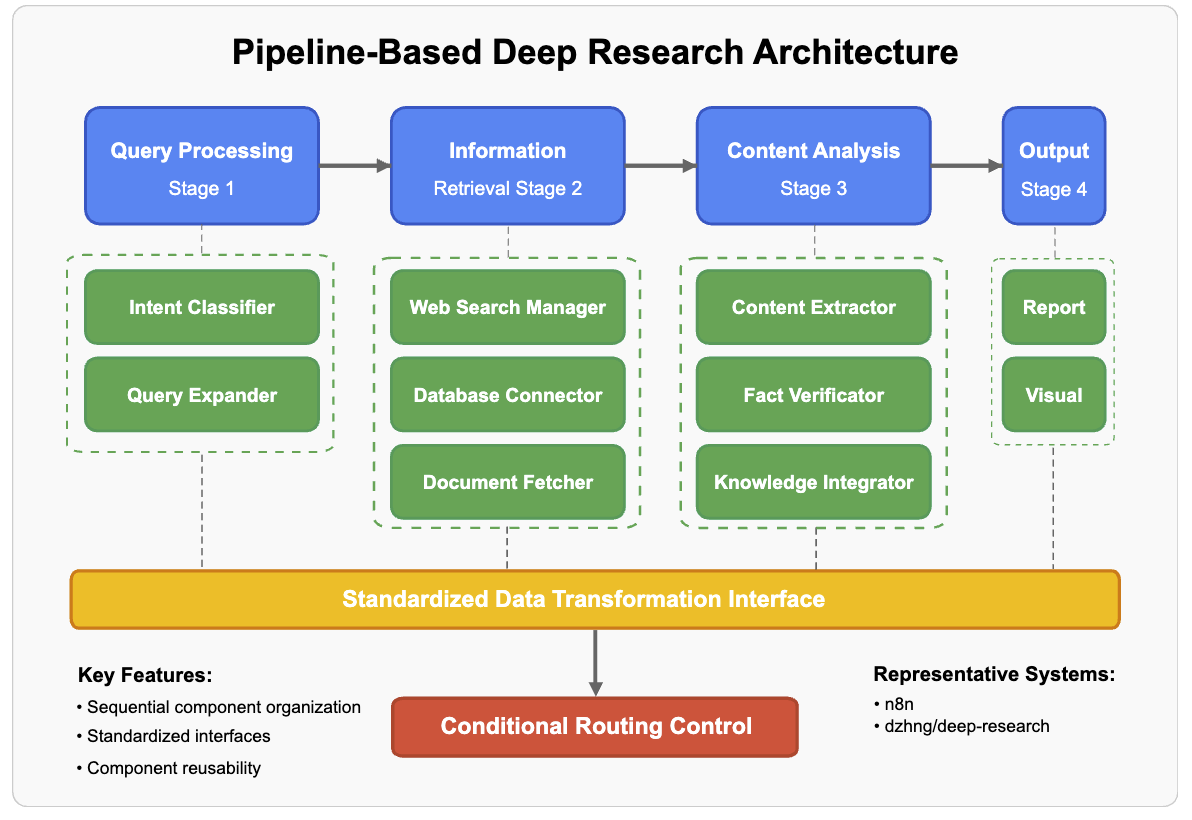
- 流水线架构(Pipeline)—— “流水线工厂”
- 核心特点:把任务拆分成多个步骤,每个步骤由专门的模块处理,像工厂的流水线一样。
- 工作方式:
- 研究任务被分解成多个阶段(比如:数据收集 → 数据分析 → 结果生成)。
- 每个阶段有专门的模块负责,数据从一个模块传到下一个模块。
- 模块之间通过标准接口通信(类似”输入-处理-输出”)。 * 优点:结构清晰,容易优化单个模块。 * 缺点:如果某个步骤卡住,整个流程会受影响。 * 类比:就像工厂生产线,A 车间负责收集原材料,B 车间负责加工,C 车间负责包装,依次传递。
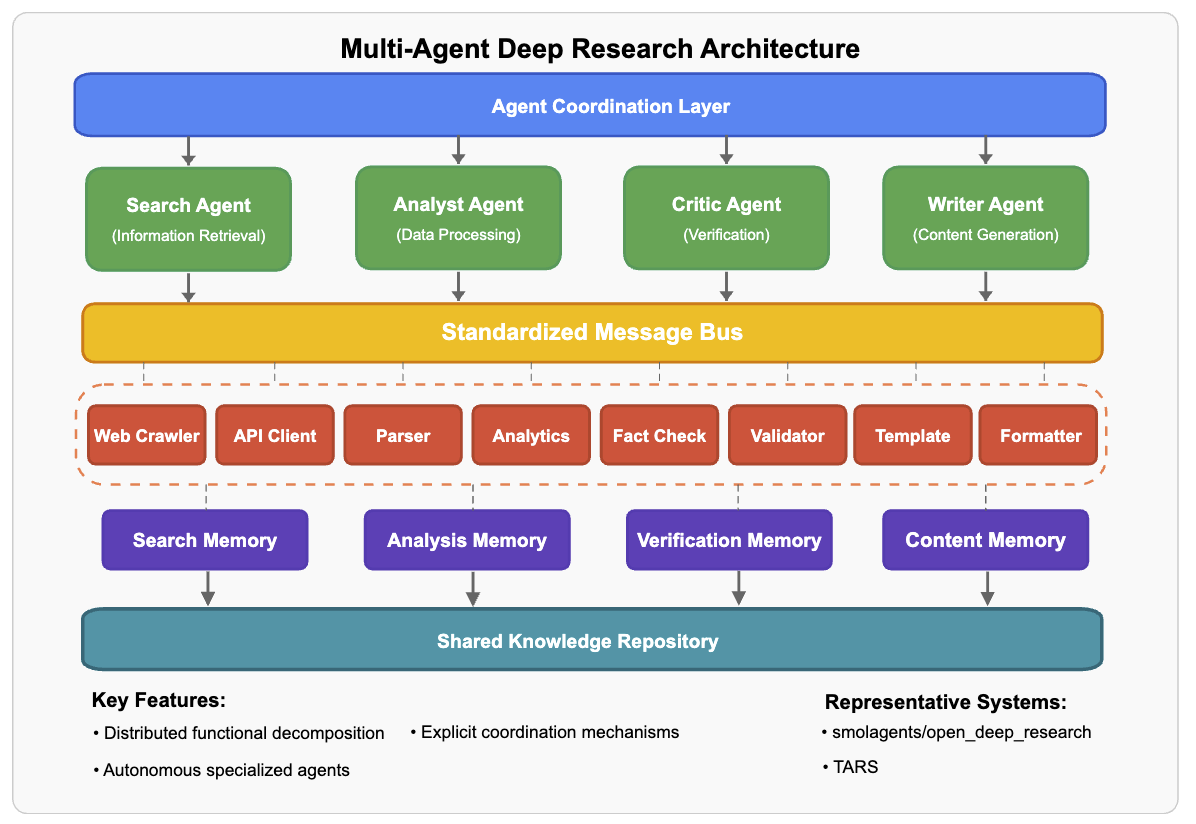
- 多智能体架构(Multi-Agent)—— “团队协作”
- 核心特点:多个”智能体”(可以理解成不同的小助手)分工合作,各自负责擅长的任务。
- 工作方式:
- 每个智能体有特定角色(比如:搜索专家、数据分析师、报告撰写员)。
- 智能体之间通过消息传递或任务分配系统协调(类似团队开会分配任务)。
- 每个智能体可以独立决策,但最终结果需要协作完成。 * 优点:灵活、可扩展,适合复杂任务。 * 缺点:协调成本高,需要设计好的通信机制。 * 类比:就像一个研究团队,有人负责查资料,有人负责分析,有人负责写总结,大家互相配合。
- 混合架构模式(Hybrid)—— “灵活组合”
- 核心特点:结合以上几种架构的优点,根据需求灵活搭配。
- 常见组合:
- 流水线 + 多智能体:某些阶段用流水线,某些阶段用多个智能体协作。
- 单体 + 智能体:核心任务用单体架构,辅助任务用智能体分担。 * 优点:平衡性能和灵活性。 * 缺点:设计复杂度高。 * 类比:就像一家公司,既有标准化的生产线(流水线),又有多个专业团队(智能体)处理特殊任务。
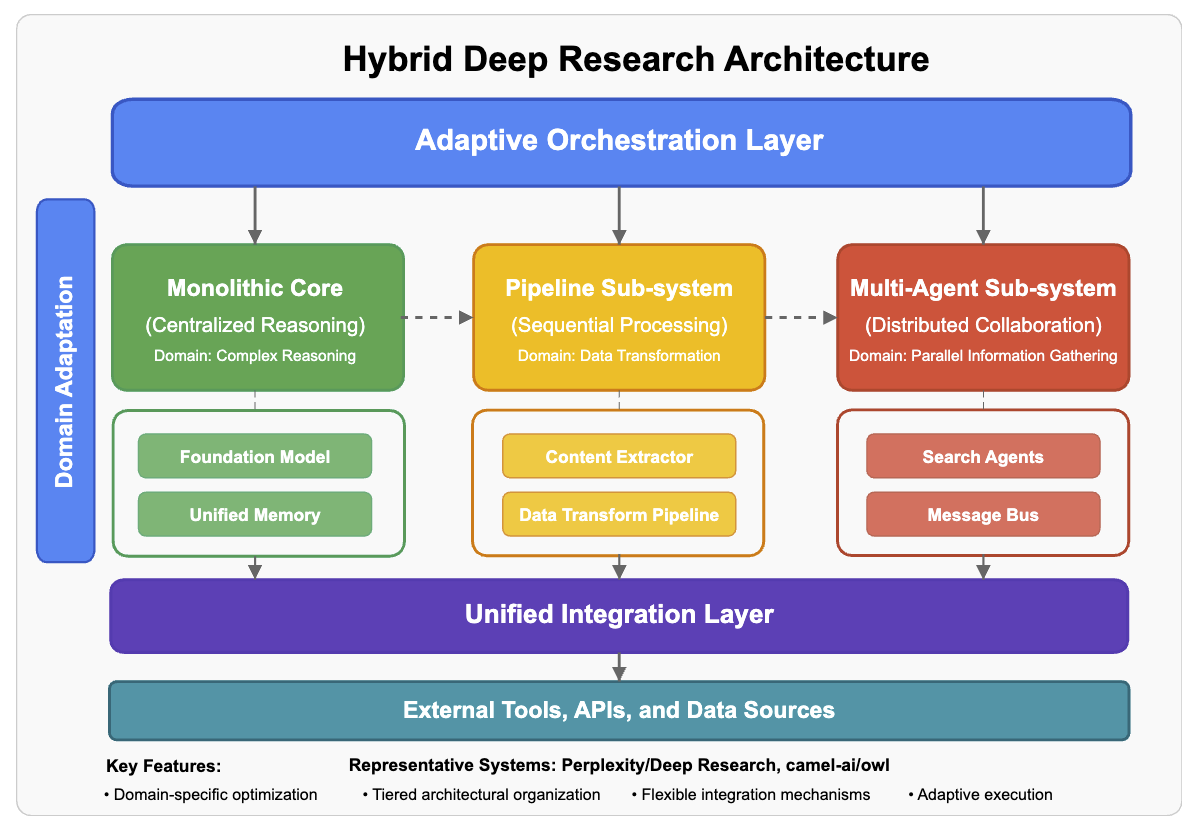
Deep Research 开源实例
这里以 Dify 平台上的 Deep Research 模板应用为例,做一个简要分析。在 Dify 的”探索应用”模板库中,有一个名为”research agent process flow”的聊天工作流。
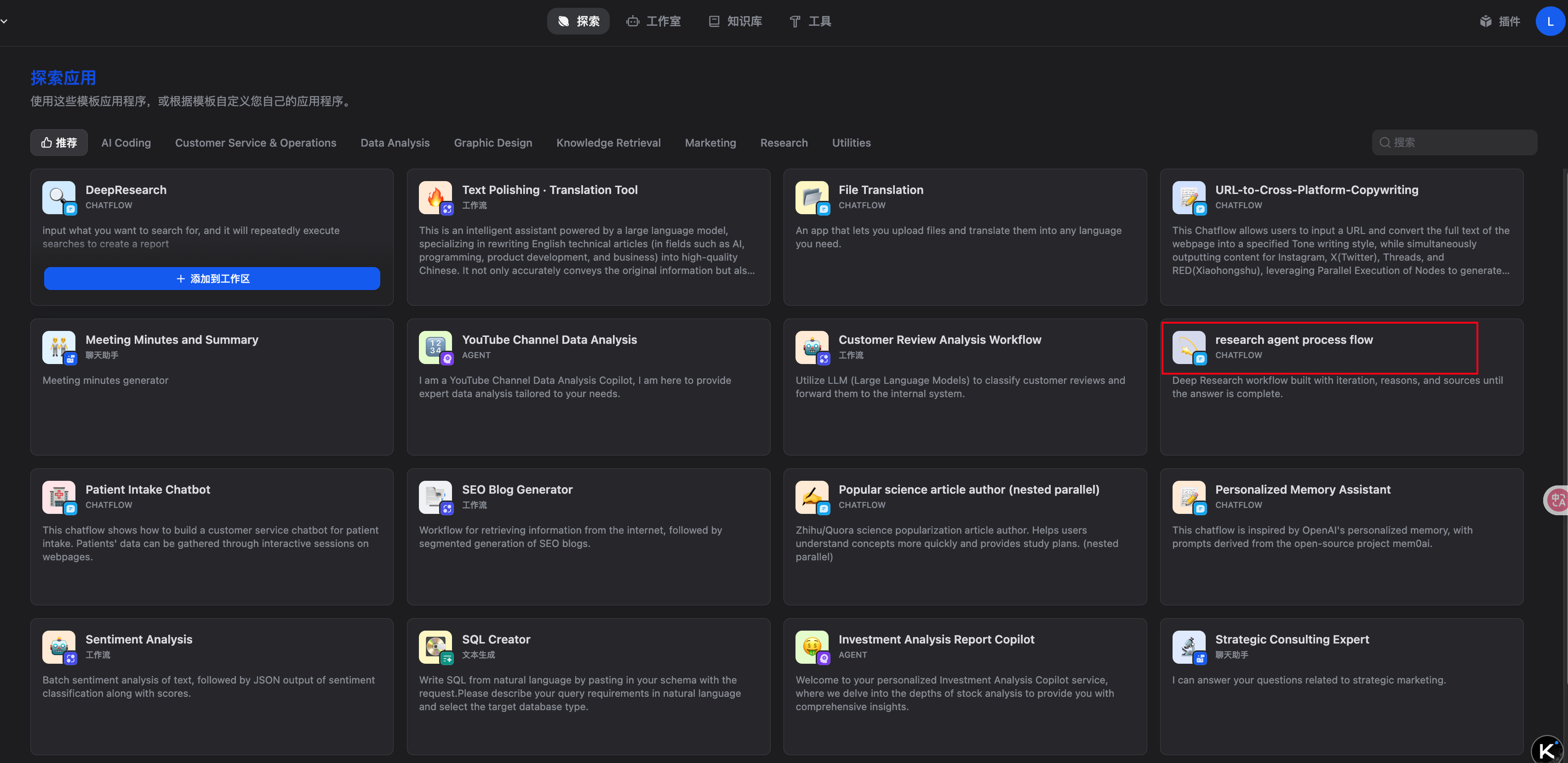 这个工作流是一个最小化的混合架构 Deep Research 实现。
这个工作流是一个最小化的混合架构 Deep Research 实现。
整个流程主要分为三个阶段:
- 意图识别:捕捉用户的研究主题,收集初始上下文,并分析目标,明确研究方向。
- 迭代探索:利用循环变量评估知识、发现信息不足,进行定向搜索,并逐步积累研究发现。
- 综合研究:将所有收集到的信息整合成结构化报告,并自动生成正确的引用。
第一阶段:意图识别
在研究开始前,用户输入背景信息和对搜索深度的要求。系统首先对用户的背景和问题进行初步分析,并通过联网搜索获取相关的实时信息。获取到上下文后,利用”答案节点流式输出”功能,避免用户长时间等待。
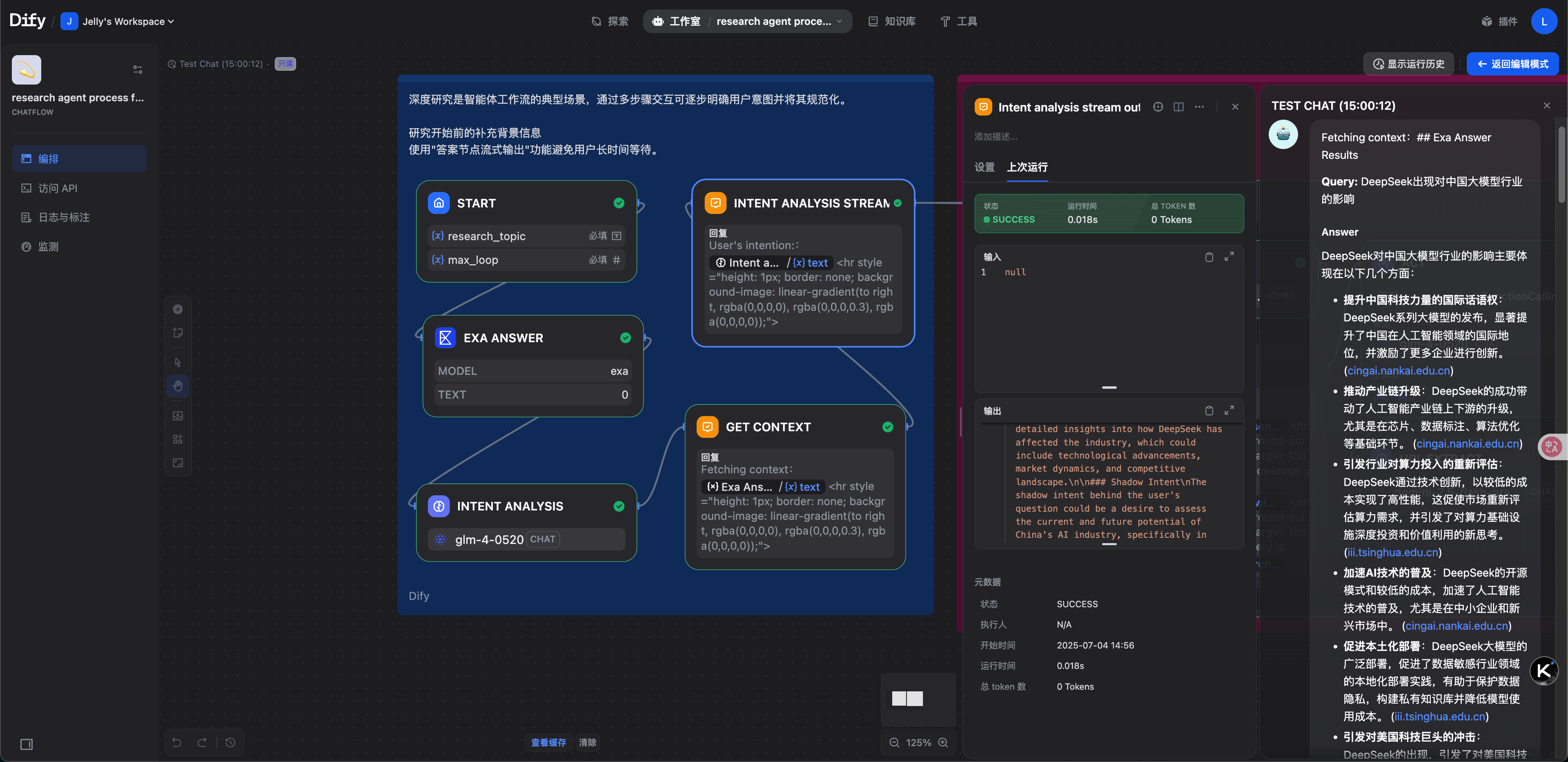
第二阶段:迭代探索
此阶段采用 ReAct(Reason + Act)策略,通过交替执行”思考”与”行动”步骤,逐步解决复杂任务。系统通过循环模式,不断迭代输出新获得的知识。
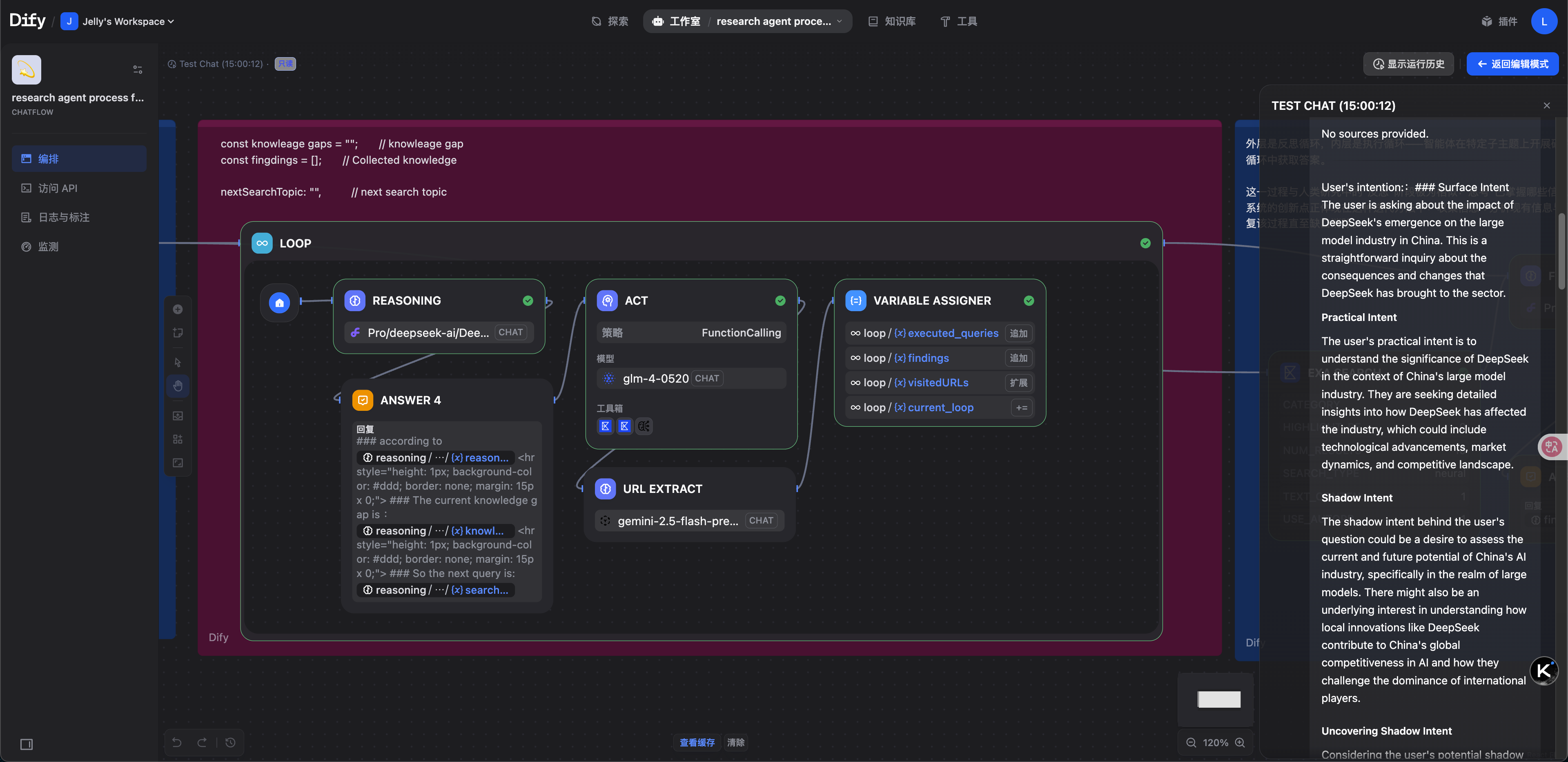
第三阶段:综合输出
当多个探索周期完成后,最终总结节点会将所有累积的变量整合,生成一份全面的研究报告。
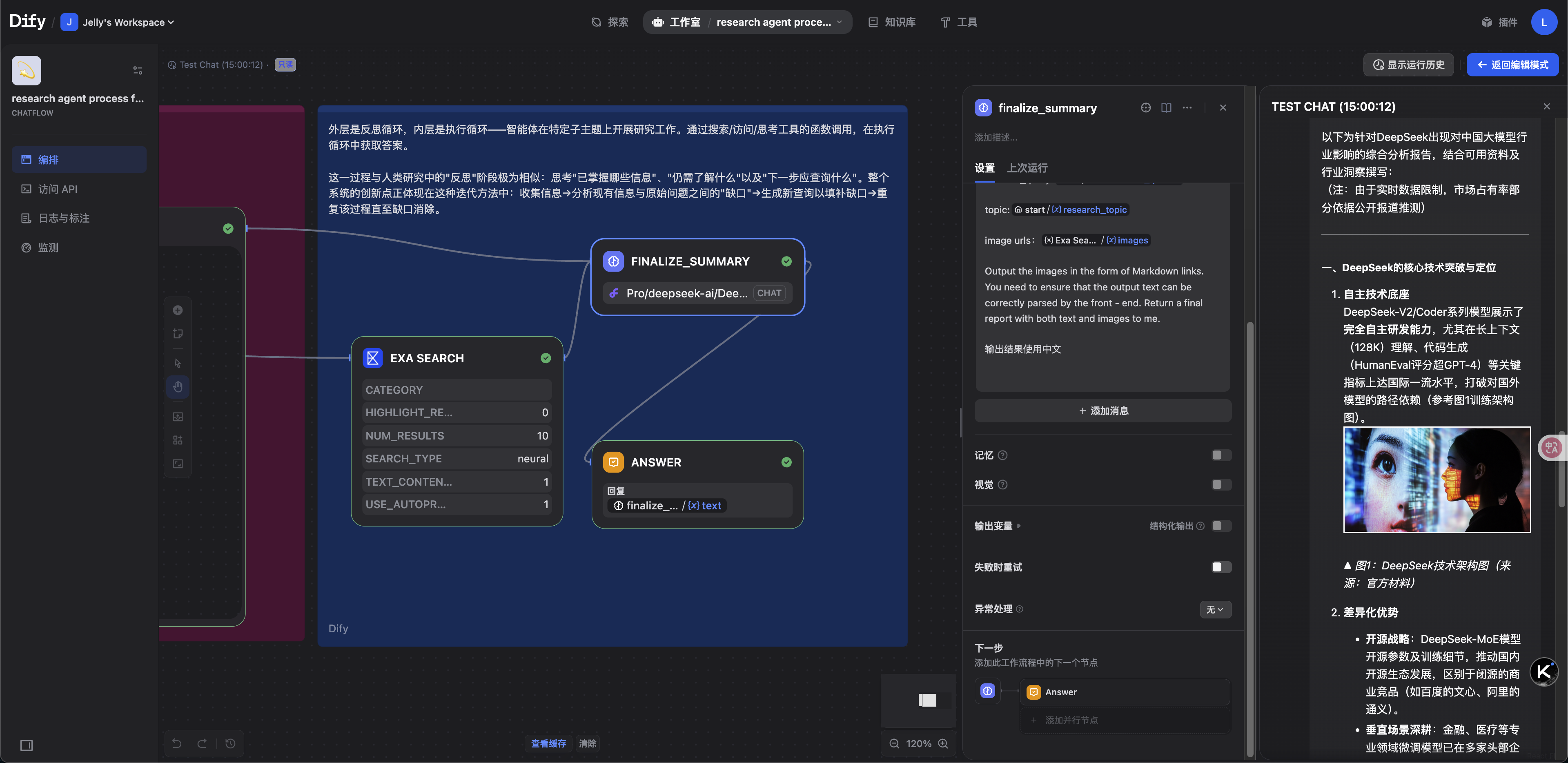
这样,就搭建好了一个最简单的能够在本地运行的Deep Research工具,在不断优化后,能够设计出适合公司或个人的产品。除此以外,如果对数据私密要求不高的情况下,还是更推荐使用Google Gemini/OpenAI(英文)、ChatGLM/Manus(中文)等成熟的Deep Research产品,能更快速地看到直观效果。
Deep Research的应用场景
Deep Research虽然在科研、教育、金融和商业智能等领域已有重要应用,但目前主要以SaaS服务形式存在,主要面向对AI先知先觉的个人用户。然而,其真正的价值爆发点在于企业级应用——这不仅是技术趋势,更是企业数字化转型的刚需。
企业级应用:Deep Research的核心战场
在企业环境中,Deep Research将面临前所未有的token消耗挑战。企业每天需要处理海量的内部文档、报告、数据分析和决策支持需求。从市场调研报告到竞品分析,从财务分析到战略规划,每个环节都需要Deep Research进行深度挖掘和智能分析。这种高频、高强度的使用模式将带来巨大的token消耗,同时也为企业创造显著的价值回报。
企业刚需:从工具到生产力的转变
对于现代企业而言,Deep Research已经从”锦上添花”的工具转变为”雪中送炭”的刚需。企业面临着信息爆炸、决策复杂化、竞争加剧等多重挑战,传统的报告生成和分析方式已无法满足快速变化的市场需求。Deep Research能够将企业内部散乱的数据转化为结构化的洞察,将复杂的研究任务自动化,让企业员工专注于更具创造性和战略性的工作。这种从工具到生产力的转变,使得Deep Research成为企业AI应用的最后一块拼图,也是token消耗最大的应用场景。
各领域应用概览
学术研究应用:深度研究系统极大提升了文献综述、假设生成、跨学科研究、数据分析、实验设计以及科研文献整合的效率和质量,使学术探索更高效、系统化。
教育领域:系统支持学习辅导、内容开发等,为个性化教育和学习支持提供智能化解决方案。
金融分析:在投资研究、尽职调查、财务趋势分析、风险评估与建模方面发挥关键作用,提升决策效率。
商业智能:帮助企业实现信息的高速整合、深度分析和智能决策,从而增强竞争力、减少决策风险,促进业务持续创新和增长。
Deep Research!为什么不是 Operator?
ChatGPT 的公司 OpenAI 目前在智能体层面推出了两个应用:第一个是 Operator,第二个是 Deep Research。那么,为什么我们更推荐 Deep Research,而不是 Operator 呢?
主要原因在于业务成熟度。Deep Research 聚焦于报告生成等单一、明确的场景,能够为用户带来直接且可衡量的价值。而 Operator 虽然定位为全能型执行代理,看似功能更强大,但在当前 Agent 工具尚不完善、交互协议不够成熟的阶段,这种”全能”反而带来了更多的不确定性和使用门槛。因此,短期内(未来 6~12 个月),Operator 在用户中的接受度并不被看好。
另一方面,从开源生态和市面上产品的丰富程度也可以看出,用户对 Deep Research 的需求显然更为强烈。同时,Deep Research 也更有可能在企业私有化部署等实际场景中落地应用。
小结
Deep Research 作为新一代智能体技术,凭借其强大的信息检索、推理和报告生成能力,极大提升了企业和个人在复杂知识获取与分析场景下的效率。无论是本地部署还是云端服务,Deep Research 都能为用户带来高质量、可追溯的研究成果。随着技术和生态的不断完善,Deep Research 有望在更多行业落地,成为推动智能化知识工作的关键引擎。
写在最后:”跟进DeepSeek部署”系列文章总结
2025年初,DeepSeek-R1的大模型性能和效果提升为人工智能行业注入了一剂强心针,企业对私有化部署DeepSeek的需求也随之急剧增长,这成为作者撰写DeepSeek私有化部署系列文章的初衷。随着用户认知的提升,大家已不再满足于一个简单的对话框,而是希望更好地使用和管理大模型,并将其真正应用于实际业务场景。因此,API Key的管控和模型联网搜索能力逐渐成为企业AI服务的刚需。随着时间推移,先行一步的用户对产品的定制化需求也日益增长,目前正处于这一阶段。大多数服务商为应对项目繁多、交付压力大的局面,普遍采取”万能牌”策略,即集成Dify、FastGPT、n8n等自动化工作流平台,以满足多样化的企业需求。
至此,私有化部署短期内的最后一道AI刚需应用正在缓缓走来,即 Deep Research——基于企业内部数据生成准确、可读性强的报告。此外,以 Operator 为代表的模型驱动自动化,是企业员工替代的重要一环。但大公司的转型速度是否足够快,以及中小企业是否需要采用私有化模型部署方案,这些问题仍有待观察。目前来看,这类应用更像是面向公有云服务的目标场景。
AI 的付费范式正在从”卖工具”转向”卖收益”。结合当前国内 AI 行业的发展现状,企业更应关注如何将 AI 技术与实际业务场景深度结合,而不仅仅是不断扩展工具功能。因此,本系列文章也将在此告一段落。
展望未来,如果 AI 的发展速度依然保持”十年百万倍”的增长态势,产品的迭代速度将远比当前的准确性更为重要。能否将 AI 技术与具体应用场景紧密结合,将成为 AI 产品快速获得用户和市场认可的关键。2025年,边缘侧模型的部署同样令人期待。例如,Google 推出的 Gemma-3n 等开源小模型,结合大厂强大且高效的云端大模型能力,将进一步推动 AI 的普及和广泛应用,深度挖掘企业与个人的多样化 AI 需求。让我们保持初心,与AI一同DeepSeek。
参考资料:
- A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications, https://arxiv.org/abs/2506.12594
- Deep Research Workflow in Dify: A Step-by-Step Guide, https://dify.ai/blog/deep-research-workflow-in-dify-a-step-by-step-guide
- Deep Research Agents: A Systematic Examination and Roadmap, https://arxiv.org/abs/2506.18096


