
作者:litianc
时间:2025年4月8日
阅读时长:6分钟
模型联网搜索的前世今生
回想第一次被OpenAI刷屏的场景,微信朋友圈里最常见的场景就是那些李白风格的藏头诗和梵高风格的DIY油画。虽然AI技术已经非常惊艳并具有想象力,但大家还不能直接用大模型来解决实际问题,以至于有了自嘲的段子:“原本期待机器人帮我们分担家务,让我们有更多时间追求诗和远方,现实却是机器人开始写诗、画画,而人类仍在为生活琐事奔波。”这里有两个重要的问题,一是如何将大模型的信息处理结果更好地对外输出;二是大模型如何从外界获取鲜艳知识。
我们知道大模型一旦训练完成,它无法立即在模型层增加新的知识,信息迭代的周期长、成本高。因此,为了解决模型最新信息不足的问题,人们提出了RAG,通过检索增强的方式在Prompt中输入少量关键的最新信息给模型。而结合网络在线搜索功能的RAG,便是大家当下用到的联网搜索。
迄今为止,联网搜索最成功的产品是Perplexity,同时几乎也是在我认知中最早推出的生成式搜索引擎。借用大模型的力量,用户可以直接提问,Perplexity 会直接从各种筛选过的来源进行总结,提供准确、直接的答案,同时提供来源参考。因此,许多人使用它替代google搜索来使用。对于国内用户而言,最早的模型联网搜索产品大约是Kimi。然而随着模型厂商跟进改造,目前各家模型厂商都在SaaS服务中原生支持模型搜索功能,联网搜索已然成为大模型的基础应用。
私有化部署是否可以开启联网搜索
既然联网搜索已经是模型应用的标配,那么私有化部署场景是否可以提供联网搜索功能?这里的关键是数据是否安全。
首先我们需要了解联网搜索到底是如何工作的。以一个标准的大模型工作流为例,如果没有接入联网搜索功能,模型会独立分析用户提出的问题,并生成答案。
如果用户开启了联网搜索功能,则会多走几个步骤:
- 首先模型服务会根据用户的问题提炼出是否需要联网搜索、搜索的关键词
- 然后通过调用联网搜索模型获得搜索结果
- 再将搜索到的内容作为模型的输入
- 进而让模型结合搜索结果生成问题的答案
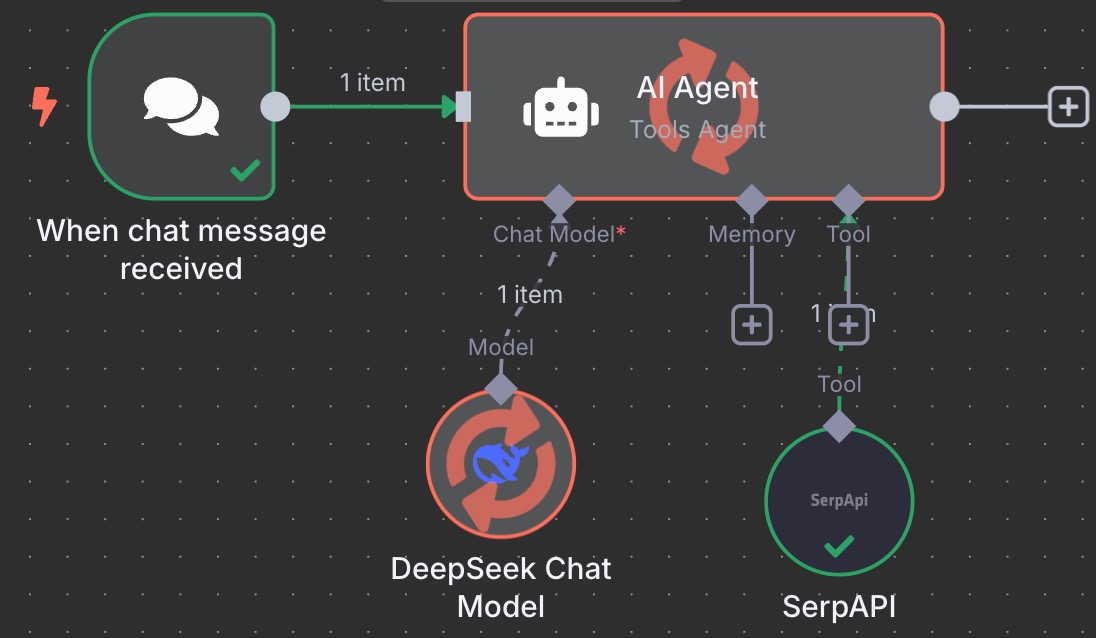

联网搜索的工作流程与对话示例
在联网搜索场景中,信息流与互联网有且只有一个相交的节点,即通过搜索引擎查询互联网上的公开信息,其他信息处理过程仍然在本地进行。
因此,我们需要根据用户的信息安全审计要求制定是否开启联网搜索的策略: 对于信息安全的相对宽松的客户,例如允许员工在日常工作中会用到在线搜索引擎,例如在政务办公写作场景中,原本制度上就是允许公务员使用政务外网的,这种情况相当于模型替代用户进行在线搜索操作,可以适当开启联网搜索功能; 但对数据安全要求非常严格的客户,工作中也不具备外网使用的条件,则应该禁用联网搜索功能。
那么,对于允许开启联网搜索的用户,应该如何选择联网搜索功能呢? 目前,从主流的模型交互框架来看,联网搜索功能主要有两种方案:
- 依赖第三方搜索引擎API,例如:SerpAPI/tavily/exa.ai,这类引擎需要用户或企业注册账号,并付费使用搜索服务。他们的优势是搜索引擎平台提供丰富和全面的搜索服务,稳定性较好,然而也存在检索信息被服务商跟踪的风险。
- 采用自建API服务,以SearXNG为代表,它提供匿名的搜索服务,并聚合多种第三方搜索引擎,对于日常企业和个人使用完全可以满足付费或免费的检索需求。由于原生抗审查、开源、可快速部署等优势,SearXNG被许多开发者作为模型联网搜索的搜索服务后台,本文也将重点介绍SearXNG的部署和使用方法。
SearXNG部署和使用
部署
本文使用的操作系统和容器管理软件版本为:ubuntu 22.04和docker 28.0.0。
- 获取 searxng-docker
git clone https://github.com/searxng/searxng-docker.git cd searxng-docker - 在docker-compose.yaml中去掉caddy配置(没有https证书需求时可以去掉)
- 删除caddy相关配置
- 将外部端口改成需要的端口号
- 以下是我使用的配置文件
version: "3.7"
services:
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
ports:
- "0.0.0.0:8085:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
valkey-data2:
- 修改.env文件中的SEARXNG_HOSTNAME
这里采用局域网共享方式,所以填写主机的ip和服务的端口号
SEARXNG_HOSTNAME=192.168.31.222:8085 - 删除searxng/setting.yml后,第一次启动 docker
命令会自动新生成一个setting.yml新文件。
rm searxng/setting.yml docker compose up -d - 停止docker,修改setting.yml
docker compose down vi searxng/setting.yml- 在formats中增加json格式
- 关闭除bing以外的所有搜索引擎 ``` bash … formats:
- html
- json … engines:
- name: bing engine: bing shortcut: bi disabled: false … ```
- 再次启动容器
docker compose up -d
以上便完成了searxng的搭建,通过浏览器访问能够看到结果则说明searxng正常启动。
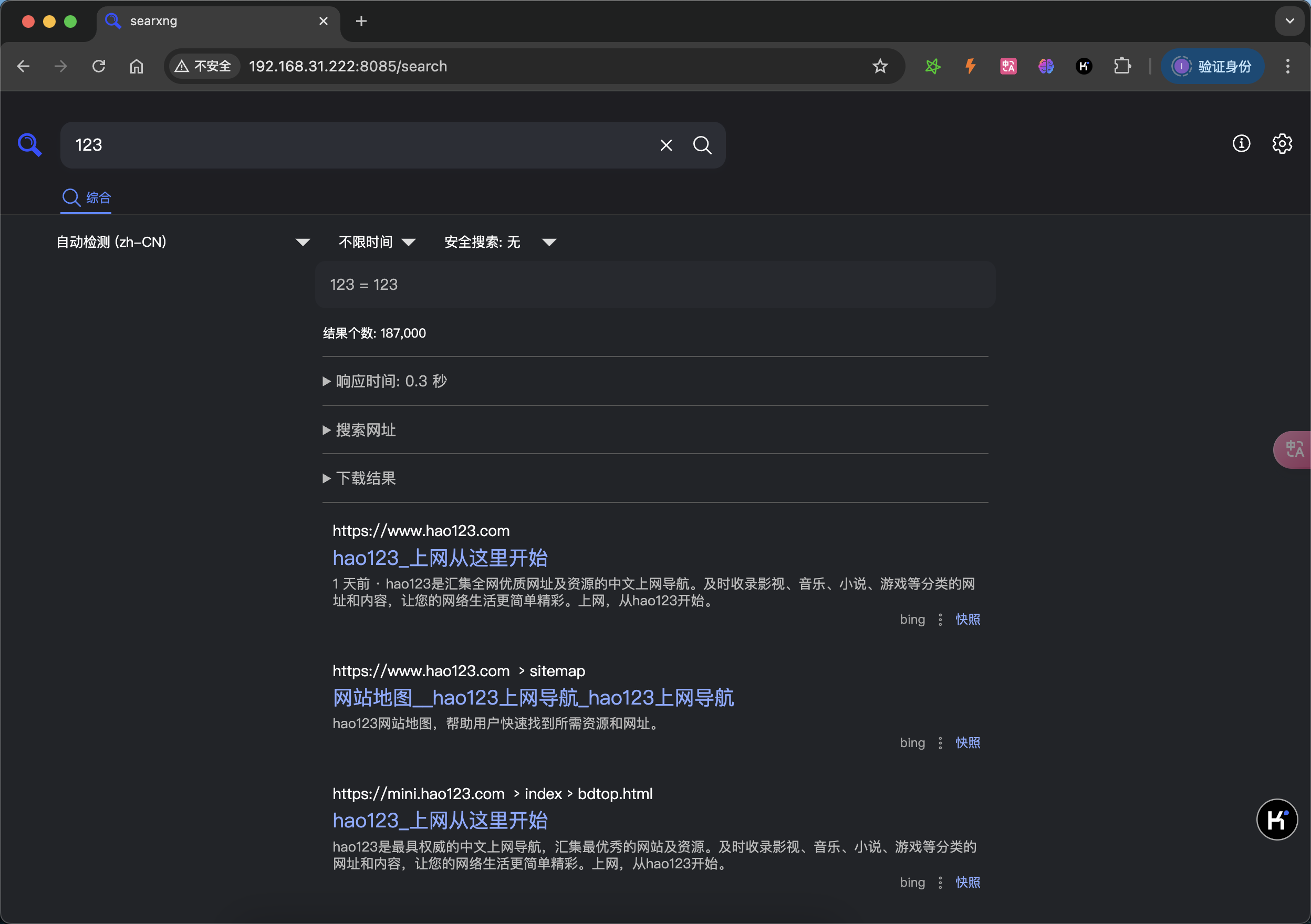
其他操作系统如windows和macos部署方式可参考网上教程。
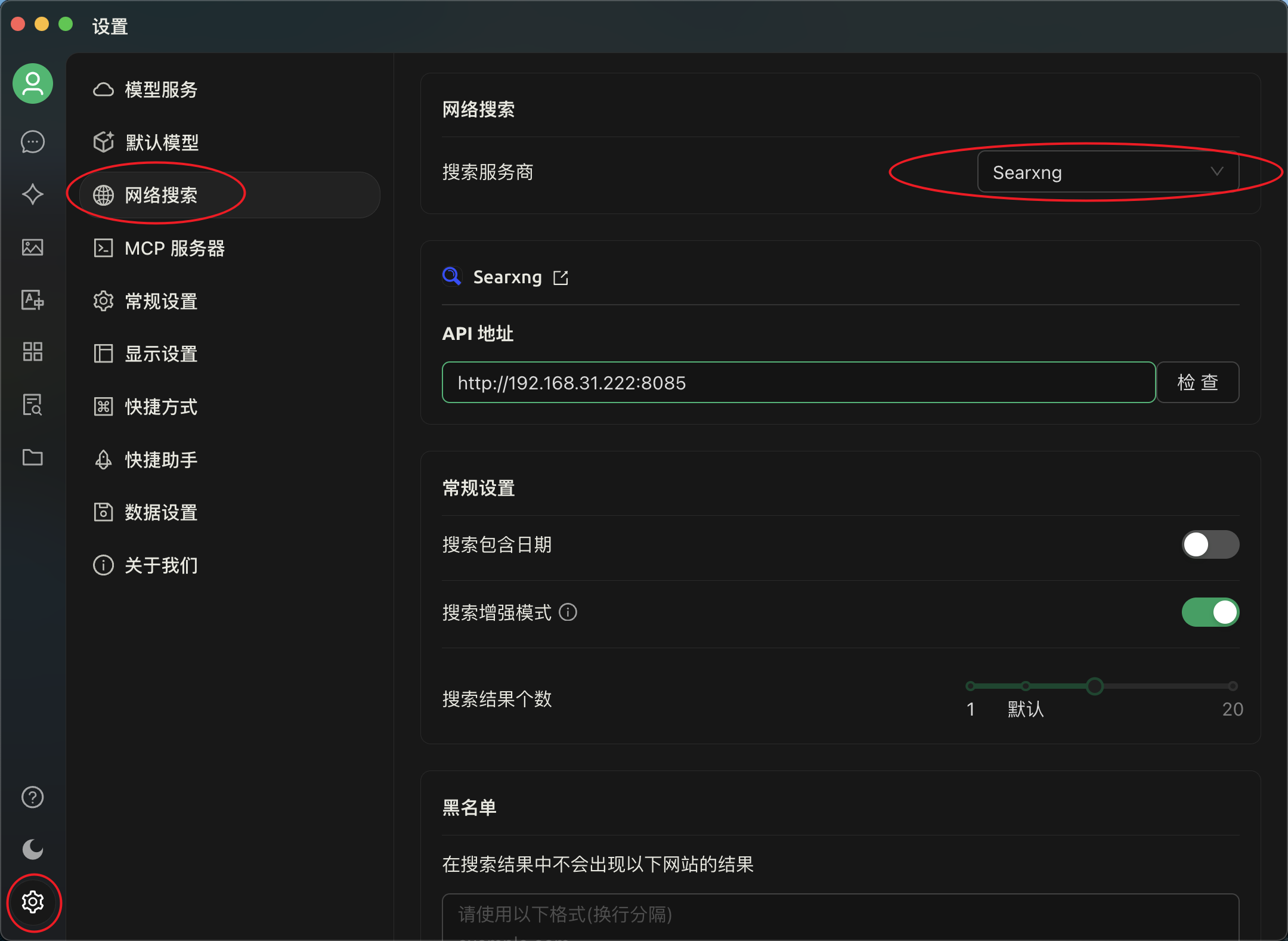
使用Cherry Studio进行联网搜索
通过Cherry studio的联网搜索选项指向我们搭建的searxng服务。
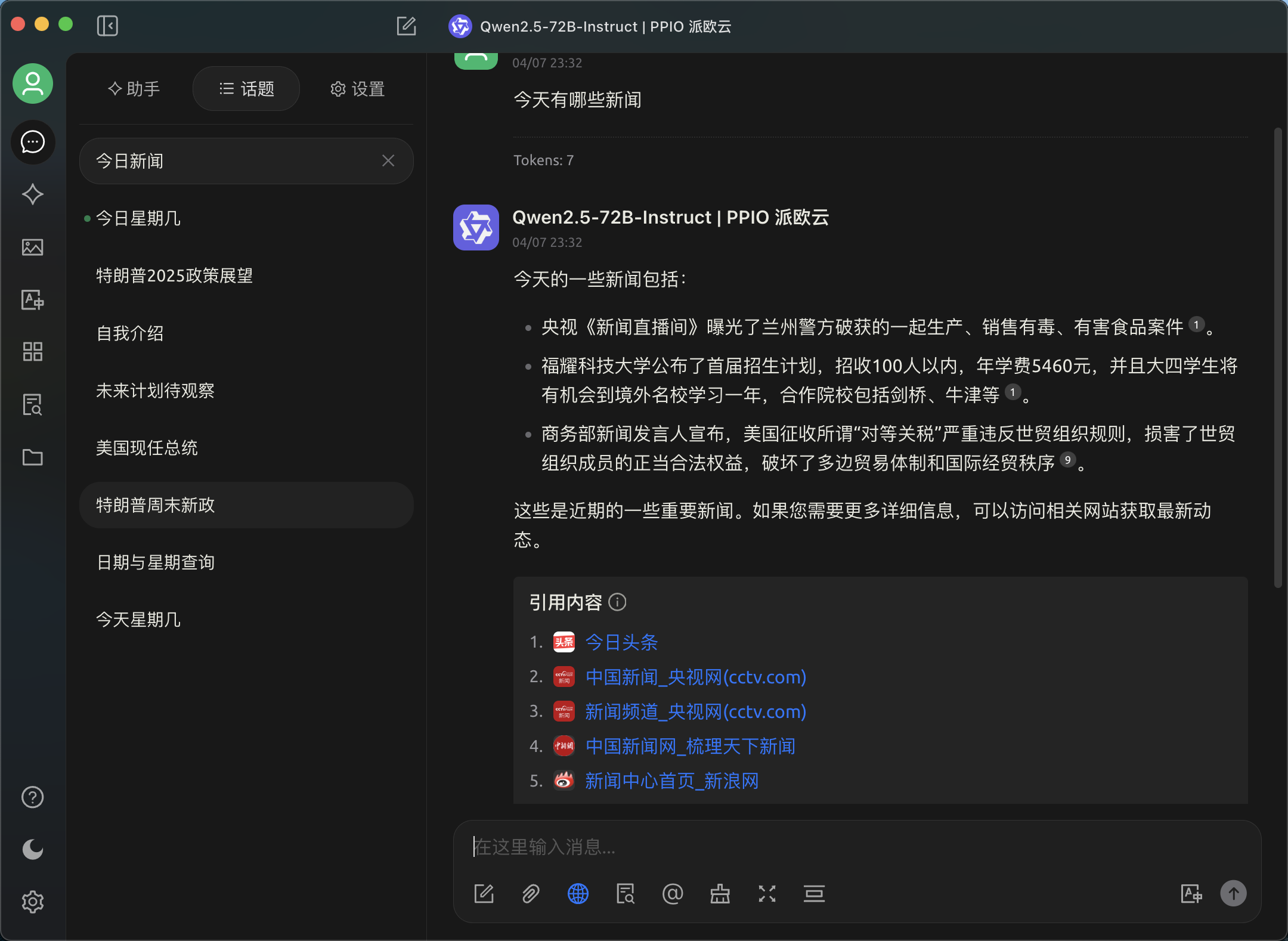
 开启联网搜索并进行模型对话。
开启联网搜索并进行模型对话。
总结
为模型注入最新的数据,同时将大模型吐出的信息更自动化的用于实际场景,我想这或许就是AI Agent的终极目标。当下,联网搜索已成为大模型的标配功能,但在私有化部署场景中如何安全实现这一功能仍是一个挑战。本文通过分析联网搜索的工作原理,提出了基于信息安全等级的使用策略建议,并详细介绍了如何使用开源的SearXNG方案来搭建私有化的搜索服务。这不仅为企业提供了一个兼顾功能性和安全性的实用方案,也为后续的大模型应用部署提供了重要的技术参考。


