
作者:litianc
时间:2025年2月4日
阅读时长:7分钟
前言
2025年春节期间,国内外媒体对 DeepSeek 高度关注。其中,最高的评价来自《黑神话·悟空》的创作者冯骥所提出的“国运级”定位。一时间,自媒体纷纷前来蹭热度,可谓热闹非凡。外行看热闹,内行看门道。可以预见的是,接下来的一段时间里,DeepSeek-R1 的本地化部署将成为国内企业级 AI 应用的首选方案。然而,目前关于 DeepSeek-R1 模型部署的文章多为混淆概念的标题党内容。因此,有必要澄清该模型的特性并提供一种经过实践的部署方法,以供学习和业务参考。
R1的特点与版本
DeepSeek-R1 系列模型在 DeepSeek-V3 的基础上通过强化学习技术,在推理能力上取得了显著突破,同时保持了低成本和开源的特点,在技术方面有如下优势:
- 证明了“强化学习”对大模型的训练效果:DS完全基于RL(强化学习)进行训练,未使用任何监督训练或人类反馈,能够通过自我学习来提高性能,减少对人工标注的依赖。
- 高性能同时做到低硬件成本:DeepSeek-R1 在数学、编程和自然语言推理等任务上的性能与 OpenAI 的 GPT-4 正式版相当,但训练成本仅为 OpenAI 同类模型的 1/30。
- 提供多种参数量的蒸馏模型,以适应不同的应用场景。
在模型版本方面,DeepSeek发布了R1系列的不同版本包括:R1-Zero、R1 和蒸馏版本。
- DeepSeek-R1-Zero:完全基于强化学习训练,未使用监督微调数据,展现出强大的推理能力,但存在可读性差和语言一致性等局限。
- DeepSeek-R1:在 R1-Zero 的基础上引入冷启动数据和多阶段训练策略,提升了模型的可读性、稳定性和语言一致性。
- 蒸馏版本:将DeepSeek-R1的推理能力迁移至 Qwen 和 LLaM 等更小规模模型中,推出了参数范围涵盖1.5B到70B的多版本。
先按下应用不会直接使用基础模型 R1-Zero。行业测评对R1和蒸馏(Distill)模型有较高评价,但值得注意的是,现有文章存在混淆R1与蒸馏模型的现象,刻意将7B、14B等蒸馏模型等同于R1的做法容易误导读者低估R1的实际部署成本。为明确区分起见,下文所述”R1”特指参数量最大的671B版本。
量化选择与软硬件要求
根据官方及社区的讨论,满血版R1(671B,且不做量化)需要2台8卡 H100,或2台8卡 H20,或1台8卡 H200来实现所有模型参数的内存卸载。如果按这种说法,只有预算至少在200万以上的企业级应用才能用上R1本地化部署。 因此,Unsloth.AI社区推出的量化版本R1可以作为使用满血版R1前的“试用装”。 ——Unsloth:我们探索了如何让更多的本地用户运行它,并设法将 DeepSeek 的 R1 671B 参数模型量化为 131GB,从原来的 720GB 减少了 80%,同时非常实用。
在实际部署中,不同的动态量化版本的效果不同:
| MoE Bits | Type | Disk Size | Accuracy | Modelscope Link |
|---|---|---|---|---|
| 1.58bit | IQ1_S | 131GB | 公平 | Link |
| 1.73bit | IQ1_M | 158GB | 好 | Link |
| 2.22bit | IQ2_XXS | 183GB | 更好 | Link |
| 2.51bit | Q2_K_XL | 212GB | 最好 | Link |
正好,我们实验室有8卡H20(每张卡96GB显存)服务器,我们接下来将用它来部署量化效果最好的2.51Bit的版本。
- 操作系统: ubuntu 22.04
- 软件:
- ollama: v0.5.7
- llama-gguf-split: 4611 (53debe6f)
- 模型: DeepSeek R1 671b 2.51-bit量化
安装步骤
安装ollama
- 下载并解压软件
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
- 启动ollama
ollama serve
下载模型文件
社区将gguf拆分成5个字文件,依次下载到本地
 https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF/files
https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF/files
也可以通过以下懒人命令下载:
pip install modelscope
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf --local_dir ~/dir
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-UD-Q2_K_XL-00002-of-00005.gguf --local_dir ~/dir
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-UD-Q2_K_XL-00003-of-00005.gguf --local_dir ~/dir
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-UD-Q2_K_XL-00004-of-00005.gguf --local_dir ~/dir
modelscope download --model unsloth/DeepSeek-R1-GGUF DeepSeek-R1-UD-Q2_K_XL-00005-of-00005.gguf --local_dir ~/dir
合并模型文件
由于当前ollama还没有支持gguf分片启动,因此,需要使用llama-gguf-split工具将刚刚得到5个字文件进行合并操作。
- 安装 llama-gguf-split
git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp cmake -B build cmake --build build --config Release # 编译好的模型文件放在llama.cpp.git/build/bin中 - 合并模型
cd build/bin ./llama-gguf-split --merge ~/dir/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf ~/dir/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-2.51bit.gguf
ollama运行启动
- 导入gguf并创建模型
cat <<EOF > ~/Modelfile FROM ~/dir/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-2.51bit.gguf TEMPLATE """<|User|><|Assistant|><|end▁of▁sentence|><|Assistant|>""" PARAMETER stop <|begin▁of▁sentence|> PARAMETER stop <|end▁of▁sentence|> PARAMETER stop <|User|> PARAMETER stop <|Assistant|> EOF cd ~ ollama create deepSeek-quant-2.51bit -f Modelfile - 验证
ollama list看到如下输出,即说明R1模型启动成功
NAME ID SIZE MODIFIED deepSeek-quant-2.51bit:latest 2be8d2cc207c 226 GB 2 minutes ago
测试效果
-
对话测试
因测试前端软件运行的本人电脑,与运行ollama和DeepSeek-R1的机器放在相同局域内网,因此,需要调整ollama配置,并重新启动。 ubuntu在默认位置/etc/systemd/system/ollama.service文件中的[Service]下面添加:
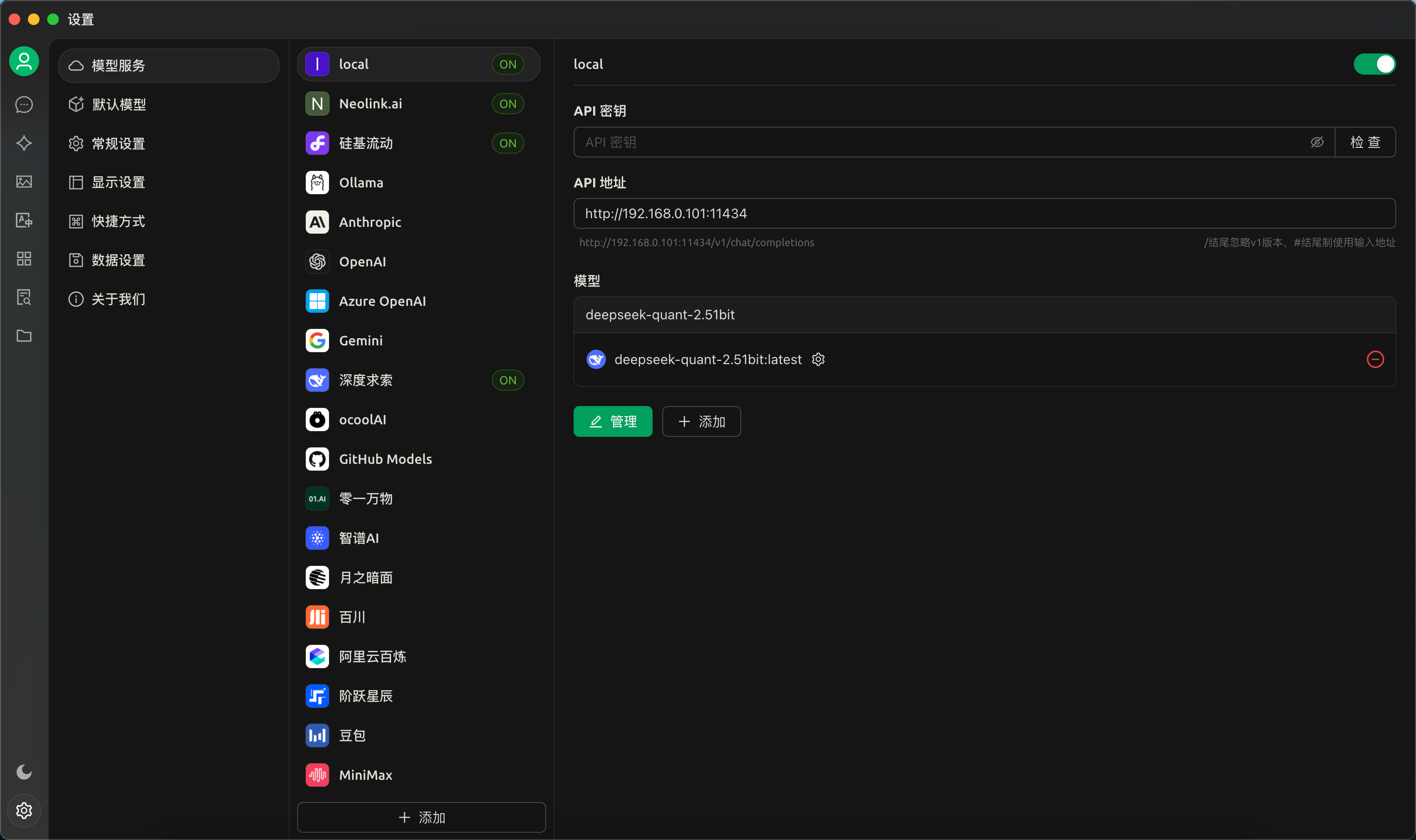
Environment="OLLAMA_HOST=0.0.0.0:11434" Environment="OLLAMA_ORIGINS=*"通过局域网的电脑中安装Cherry Studio软件,并配置添加后台API信息,以我的环境为例,添加了一条命名为“local”的OpenAI类型的模型服务接口(如下图)。
在对话页面,就可以像其他网页大模型一样跟我们搭建好的本地大模型进行对话,。
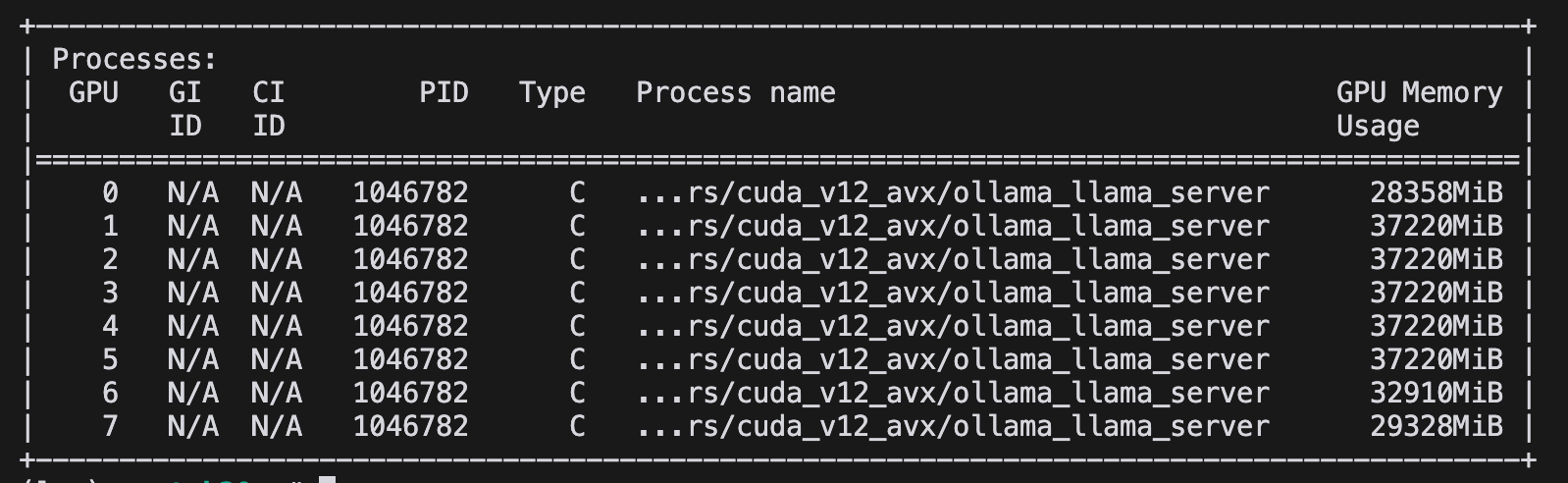
此时,在后台查看GPU使用情况,可以看到GPU内存平均每张卡占用30GB左右。
-
测试启动模型的最小GPU卡数
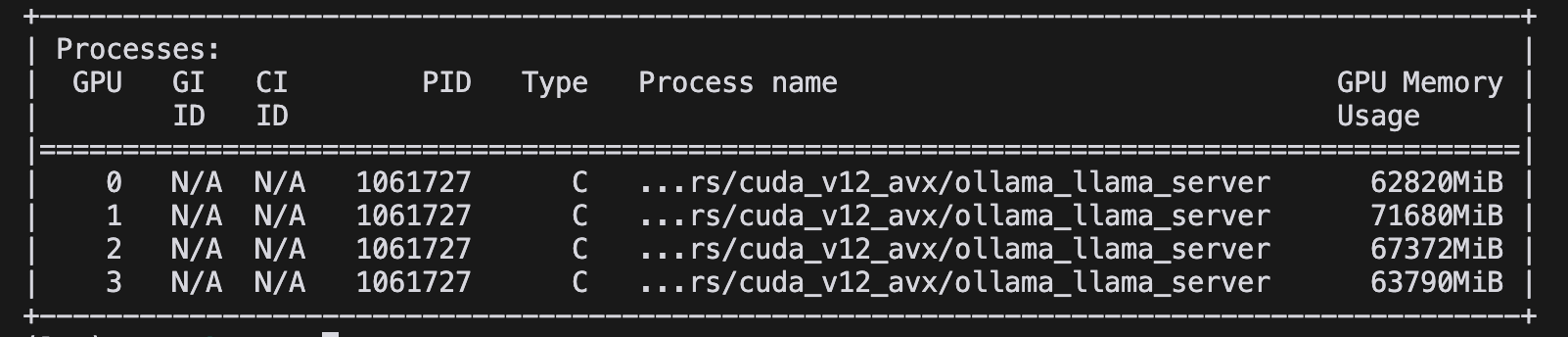
减少GPU卡重新运行,如果将GPU卡减少到4块,实际使用的是序号为“0、1、2、3”四块GPU,在提问相同问题时,GPU的显存占用翻倍。
进一步如果将GPU卡减少到2块,在提问相同问题时,发现GPU的显存溢出,无法提供正确的回答。
因此,用ollama运行DeepSeek-R1-2.51Bit量化版本,建议使用3~4块H20。
-
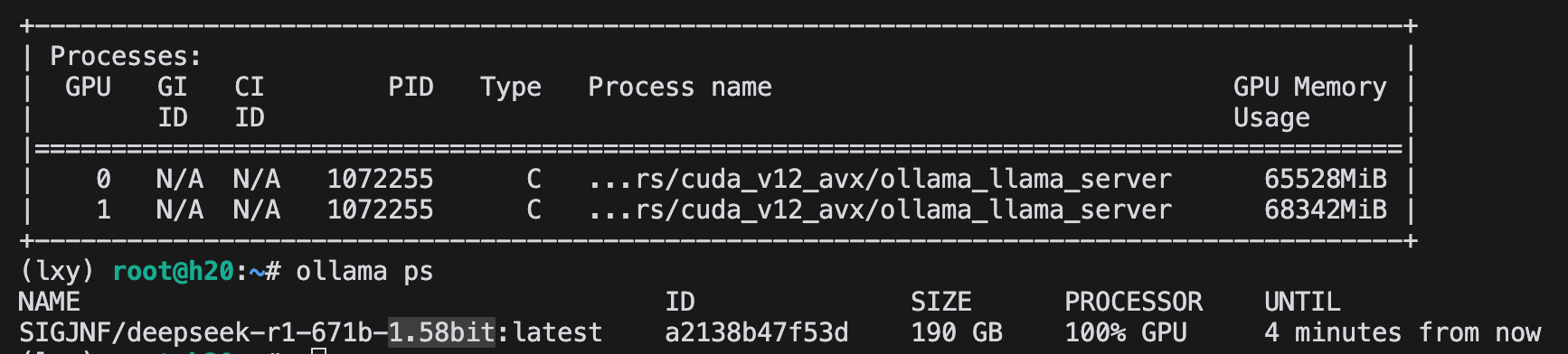
测试1.58-bit量化所需卡数
进一步降低量化精度,采用1.58-bit量化版本,实际测试两块H20显卡能够运行成功。
总结
DeepSeek-R1系列发布了8个开源模型,其中原生DeepSeek的只有R1-Zero和R1,其他模型则是基于DeepSeek基础模型进行知识蒸馏,并采用Qwen或LLaMA架构的二次开发版本。本文动手部署了原生的R1版,当然受限于硬件条件限制采用了2.51-bit量化方案,并实际测试得出需要使用4块H20来进行部署2.51-bit量化的版本,需要2块H20来部署1.58-bit量化的版本。此外,根据社区的一些分析,R1经1.58-bit量化后最小可以部署在1张4090卡上,当然这种情况需要反复加载激活参数,对推理速度有较大的影响。
接下来,我还打算将本地部署的DeekSeek-R1接入我们之前的《我的世界》游戏看看DeepSeek搭建的建筑效果如何。此外,后续有时间希望动手尝试一下用2台H20部署满血版DeekSeek-R1。
参考资料
- https://unsloth.ai/blog/deepseekr1-dynamic
- https://www.reddit.com/r/LocalLLaMA/comments/1ibbloy/158bit_deepseek_r1_131gb_dynamic_gguf/


